
The Very Large Array Sky Survey is observing 33,885 square degrees of the sky over seven years, mapping 82 percent of the total sky from its position in New Mexico. The sky survey generates terabytes of data on a daily basis, and so far, scientists are able to process this astronomical amount of data in real time, pushing computing power to its limits. Our data storage capabilities have kept pace with the massive output from these electronic galaxy gazers, but the real struggle has been trying to figure out how to synthesize all of that output. Two of our scientists, Brian and Joe, write about some of the challenges they encountered trying to process this tsunami of information within a highly specialized data processing pipeline.
Radio astronomers certainly know how to fill hard drives quickly! Carrying out larger observations mean that we are accumulating greater amounts of data with our radio telescopes, and new methods need to be devised to handle the data flow. The Very Large Array Sky Survey (VLASS) is a new project undertaken by the NRAO and its community of scientists and astronomers, observing the entire sky from New Mexico at a radio frequency of 2 to 4 GHz (a range known as S-band). In the past, a user could generate a single image from a single target in the sky, but now these large-scale sky surveys gather data from a large swath of the sky creating tens of thousands of images and recording millions of objects in the Universe. Building on previous radio surveys with the VLA (Figure 1), like FIRST (Faint Images of the Radio Sky at Twenty-one centimeters) and NVSS (The 1400 MHz NRAO VLA Sky Survey), VLASS takes data processing requirements to an exciting new level.
Why do we need data processing pipelines to handle these observations? Consider that every half second VLASS records data from 27 radio telescopes, with over 1000 frequency channels, to a sky resolution of about one arcsecond (1/2000th the diameter of the full moon!). The result is a data rate upwards of 90 Gigabytes per hour. We could fill an iPhone’s storage capacity in less than 20 minutes! Over the course of eight years, VLASS will generate over 500 terabytes of raw data alone, and that is even before the survey team of scientists and engineers calibrate and image what comes off the telescope. It is a challenging scenario for manual data reduction, and this means the project has to have an automated pipeline.

So what kind of technology is involved? Well, the data reduction pipeline builds upon in-house software called CASA – the Common Astronomy Software Applications package. CASA is written by software engineers in a programming language called C++. The pipeline is written in a language called Python, make decisions about the data calibration, and then uses CASA to do the sophisticated number crunching. Python has grown in popularity, not only in astronomy but also in many areas of software engineering and development, as it gives users scripting capabilities to analyze data, as well as object-oriented coding constructs for engineers to produce maintainable and well-structured applications. The pipeline uses decision-making criteria determined by VLA experts and built into the software to determine how to prepare the data for users. The automation of the pipeline allows the data crunching to be completed as quickly as possible. The pipeline is executed automatically without human intervention, although a human will participate in the careful quality assurance process to ensure the data are ready for scientific exploration.
The pipeline imports an observation into a data format called a measurement set. All relevant metadata information (target names and intent types, frequencies, and scan information) is stored so that it is easily accessible. Next, we remove data that are not usable from consideration, due to radio frequency interference (RFI), system issues, or telescope shadowing in a process called data flagging.
During any kind of astronomical observing session, short observations must be made of targets called calibrators. For radio observations, these calibrator sources are typically distant galaxies (known as quasars) of known stable intensity. We use these sources to set the calibration scale, to anchor our observation within a known fixed source. In addition, we obtain periodic observations of another astronomical source nearby in the sky to aid in the phase calibration.
After calibration, the last step of the pipeline is to create images with the data. These images come in several varieties, each related to a different phase of the sky survey. The pipeline produces “Quick-look” images – these are made publicly available in a matter of days. Each image is one square degree of the sky and may contain thousands of objects. “Single epoch” images, made available months after the observations, cover the same region but with greater fidelity and include additional information about the objects’ polarization properties. Finally, “cumulative” images are like the “single epoch” images but combine data observed of the same region of the sky many months apart. Each target will be observed three times, and with each observation, the images we can produce become more and more accurate. As of late February 2018, we have created 7,200 sq. deg. of “quick look” images (approximately 93,000 megapixels). Remember that the full moon subtends just one-half a degree (or 30 arcminutes) on the sky! All standard VLA observation blocks, as well as the VLASS project, are currently processed through the pipeline software.
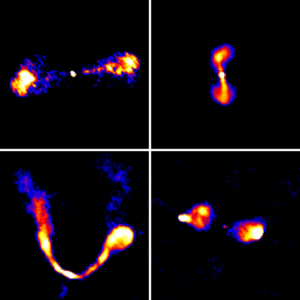
What is the project discovering? Figure 2 shows a very small subset of objects from all those images. Each image is two arcminutes on a side and these are just the preliminary results – VLASS participants will catalog millions of objects. These distant radio galaxies, previously unresolved by any telescope or project, show the power of interferometric imaging coupled with modern hardware and software. The VLASS project and pipeline will continue to produce scientific products for the astronomical community for the next eight years – stay tuned!
References:
- http://www.python.org/
- https://www.tiobe.com/tiobe-index/
- http://vlass.org
- https://casa.nrao.edu/
- https://science.nrao.edu/facilities/vla/data-processing/pipeline
- https://ned.ipac.caltech.edu/level5/Sept11/Antonucci/frames.html
- Galactic and Extragalactic Radio Astronomy: http://adsabs.harvard.edu/abs/1988gera.book…..K



